For developing the understanding of Linux RCU we shall first go ahead with the the Paul McKenney's explanation on YouTube.
https://www.youtube.com/watch?v=obDzjElRj9c
This helps a lot in understanding the concept behind RCU.
Next we try to execute RCU examples from here : https://www.kernel.org/doc/html/latest/RCU/whatisRCU.html#what-are-some-example-uses-of-core-rcu-api
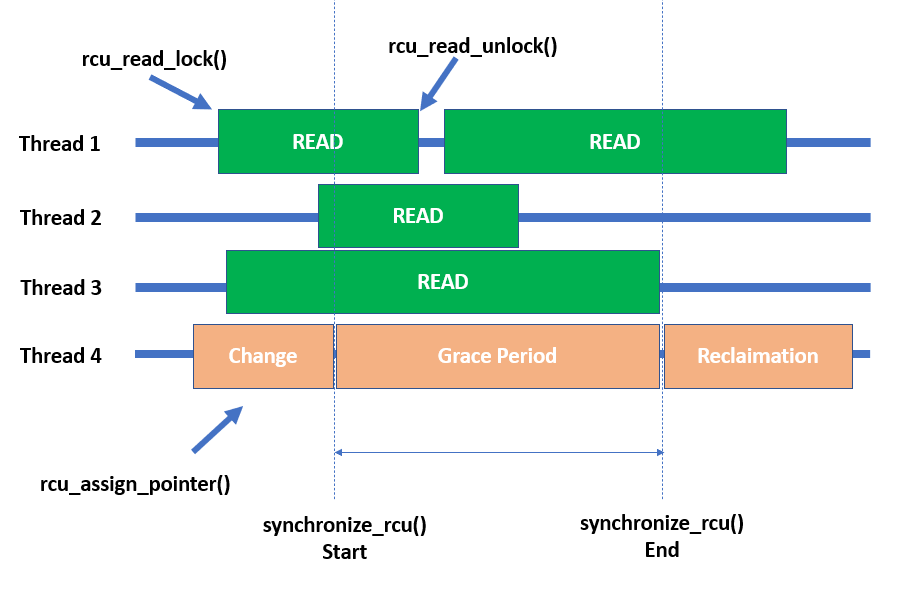
Sample kernel module to test the core APIS of RCU :
#include<linux/module.h>
#include<linux/version.h>
#include<linux/kernel.h>
#include<linux/init.h>
#include<linux/kprobes.h>
#include<linux/spinlock.h>
#include<linux/slab.h>
#include<linux/rcupdate.h>
struct foo {
int a;
char b;
long c;
};
DEFINE_SPINLOCK(foo_mutex);
struct foo __rcu *gbl_foo;
void foo_init_a(int new_a)
{
struct foo *fp = NULL;
fp = kmalloc(sizeof(*fp), GFP_KERNEL);
fp->a = new_a;
gbl_foo = fp;
}
void foo_update_a(int new_a)
{
struct foo *new_fp;
struct foo *old_fp;
new_fp = kmalloc(sizeof(*new_fp), GFP_KERNEL);
spin_lock(&foo_mutex);
old_fp = rcu_dereference_protected(gbl_foo, lockdep_is_held(&foo_mutex));
*new_fp = *old_fp;
new_fp->a = new_a;
rcu_assign_pointer(gbl_foo, new_fp);
printk("updated pointer\n");
spin_unlock(&foo_mutex);
printk("synchronize rcu\n");
synchronize_rcu();
kfree(old_fp);
}
int foo_get_a(void)
{
int retval;
rcu_read_lock();
retval = rcu_dereference(gbl_foo)->a;
rcu_read_unlock();
printk("%s, %d fetched val is %d\n", __func__, __LINE__, retval);
return retval;
}
void foo_del_a(void)
{
if(gbl_foo != NULL)
kfree(gbl_foo);
}
int myinit(void)
{
printk("module inserted\n");
foo_init_a(70);
foo_get_a();
foo_get_a();
foo_update_a(20);
foo_get_a();
foo_update_a(30);
foo_get_a();
foo_del_a();
return 0;
}
void myexit(void)
{
printk("module removed\n");
}
module_init(myinit);
module_exit(myexit);
MODULE_AUTHOR("K_K");
MODULE_DESCRIPTION("RCU MODULE");
MODULE_LICENSE("GPL");
#include<linux/version.h>
#include<linux/kernel.h>
#include<linux/init.h>
#include<linux/kprobes.h>
#include<linux/spinlock.h>
#include<linux/slab.h>
#include<linux/rcupdate.h>
struct foo {
int a;
char b;
long c;
};
DEFINE_SPINLOCK(foo_mutex);
struct foo __rcu *gbl_foo;
void foo_init_a(int new_a)
{
struct foo *fp = NULL;
fp = kmalloc(sizeof(*fp), GFP_KERNEL);
fp->a = new_a;
gbl_foo = fp;
}
void foo_update_a(int new_a)
{
struct foo *new_fp;
struct foo *old_fp;
new_fp = kmalloc(sizeof(*new_fp), GFP_KERNEL);
spin_lock(&foo_mutex);
old_fp = rcu_dereference_protected(gbl_foo, lockdep_is_held(&foo_mutex));
*new_fp = *old_fp;
new_fp->a = new_a;
rcu_assign_pointer(gbl_foo, new_fp);
printk("updated pointer\n");
spin_unlock(&foo_mutex);
printk("synchronize rcu\n");
synchronize_rcu();
kfree(old_fp);
}
int foo_get_a(void)
{
int retval;
rcu_read_lock();
retval = rcu_dereference(gbl_foo)->a;
rcu_read_unlock();
printk("%s, %d fetched val is %d\n", __func__, __LINE__, retval);
return retval;
}
void foo_del_a(void)
{
if(gbl_foo != NULL)
kfree(gbl_foo);
}
int myinit(void)
{
printk("module inserted\n");
foo_init_a(70);
foo_get_a();
foo_get_a();
foo_update_a(20);
foo_get_a();
foo_update_a(30);
foo_get_a();
foo_del_a();
return 0;
}
void myexit(void)
{
printk("module removed\n");
}
module_init(myinit);
module_exit(myexit);
MODULE_AUTHOR("K_K");
MODULE_DESCRIPTION("RCU MODULE");
MODULE_LICENSE("GPL");
Makefile :
obj-m += rcu_example.o
all :
make -C /lib/modules/`uname -r`/build M=$(PWD) modules
clean :
make -C /lib/modules/`uname -r`/build M=$(PWD) clean
We can also look at userspace RCU implementation :
Userspace RCU is present here (examples also present):
RCU all flavors API :
Lets see write a program with linked list rcu API usage :
#include<linux/module.h>
#include<linux/version.h>
#include<linux/kernel.h>
#include<linux/init.h>
#include<linux/kprobes.h>
#include<linux/spinlock.h>
#include<linux/slab.h>
#include<linux/rcupdate.h>
#include<linux/rculist.h>
#include<linux/list.h>
struct foo {
struct list_head list;
int a;
char b;
long c;
};
struct list_head head = LIST_HEAD_INIT(head);
DEFINE_SPINLOCK(foo_mutex);
void add_foo_to_list(int a, int b, int c)
{
struct foo *p;
printk("%s\n", __func__);
p = kmalloc(sizeof(*p), GFP_KERNEL);
p->a = a;
p->b = b;
p->c = c;
spin_lock(&foo_mutex);
list_add_rcu(&p->list, &head);
spin_unlock(&foo_mutex);
synchronize_rcu();
}
void print_list(void)
{
struct foo *p;
printk("%s\n", __func__);
rcu_read_lock();
list_for_each_entry_rcu(p, &head, list) {
printk("a = %d, b = %d, c = %ld\n", p->a, p->b, p->c);
}
rcu_read_unlock();
}
void del_list(void)
{
struct foo *p;
printk("%s\n", __func__);
spin_lock(&foo_mutex);
list_for_each_entry_rcu(p, &head, list) {
printk("a = %d, b = %d, c = %ld\n", p->a, p->b, p->c);
list_del_rcu(&p->list);
}
spin_unlock(&foo_mutex);
synchronize_rcu();
}
int myinit(void)
{
printk("module inserted\n");
add_foo_to_list(10,20,30);
add_foo_to_list(11,22,33);
add_foo_to_list(14,25,36);
print_list();
add_foo_to_list(17,28,39);
print_list();
del_list();
return 0;
}
void myexit(void)
{
printk("module removed\n");
}
module_init(myinit);
module_exit(myexit);
MODULE_AUTHOR("K_K");
MODULE_DESCRIPTION("RCU MODULE");
MODULE_LICENSE("GPL");
Sleepable RCU details are present here : https://lwn.net/Articles/202847/
Same implementation with SRCU APIs :
#include<linux/module.h>
#include<linux/version.h>
#include<linux/kernel.h>
#include<linux/init.h>
#include<linux/kprobes.h>
#include<linux/spinlock.h>
#include<linux/slab.h>
#include<linux/rcupdate.h>
#include<linux/rculist.h>
#include<linux/list.h>
struct foo {
struct list_head list;
int a;
char b;
long c;
};
struct list_head head = LIST_HEAD_INIT(head);
struct srcu_struct my_srcu;
DEFINE_SPINLOCK(foo_mutex);
void add_foo_to_list(int a, int b, int c)
{
struct foo *p;
printk("%s\n", __func__);
p = kmalloc(sizeof(*p), GFP_KERNEL);
p->a = a;
p->b = b;
p->c = c;
spin_lock(&foo_mutex);
list_add_rcu(&p->list, &head);
spin_unlock(&foo_mutex);
synchronize_srcu(&my_srcu);
}
void print_list(void)
{
struct foo *p;
int srcu_idx;
printk("%s\n", __func__);
srcu_idx = srcu_read_lock(&my_srcu);
list_for_each_entry_rcu(p, &head, list) {
printk("a = %d, b = %d, c = %ld\n", p->a, p->b, p->c);
}
srcu_read_unlock(&my_srcu, srcu_idx);
}
void del_list(void)
{
struct foo *p;
printk("%s\n", __func__);
spin_lock(&foo_mutex);
list_for_each_entry_rcu(p, &head, list) {
printk("a = %d, b = %d, c = %ld\n", p->a, p->b, p->c);
list_del_rcu(&p->list);
}
spin_unlock(&foo_mutex);
synchronize_srcu(&my_srcu);
}
int myinit(void)
{
int ret = 0;
printk("module inserted\n");
ret = init_srcu_struct(&my_srcu);
if (ret)
goto exit;
add_foo_to_list(10,20,30);
add_foo_to_list(11,22,33);
add_foo_to_list(14,25,36);
print_list();
add_foo_to_list(17,28,39);
print_list();
del_list();
exit:
return 0;
}
void myexit(void)
{
cleanup_srcu_struct(&my_srcu);
printk("module removed\n");
}
module_init(myinit);
module_exit(myexit);
MODULE_AUTHOR("K_K");
MODULE_DESCRIPTION("RCU MODULE");
MODULE_LICENSE("GPL");
Lets look at the rcu_read_lock() : The description says "it is illegal to block while in an RCU read-side critical section." In the case of preemptible kernel the rcu read critical section may get preempted.
Its implementation :)
static __always_inline void rcu_read_lock(void)
{
__rcu_read_lock();
__acquire(RCU);
rcu_lock_acquire(&rcu_lock_map);
RCU_LOCKDEP_WARN(!rcu_is_watching(),
"rcu_read_lock() used illegally while idle");
}
#ifdef CONFIG_PREEMPT_RCU
void __rcu_read_lock(void);
void __rcu_read_unlock(void);
/*
* Defined as a macro as it is a very low level header included from
* areas that don't even know about current. This gives the rcu_read_lock()
* nesting depth, but makes sense only if CONFIG_PREEMPT_RCU -- in other
* types of kernel builds, the rcu_read_lock() nesting depth is unknowable.
*/
#define rcu_preempt_depth() (current->rcu_read_lock_nesting)
#else /* #ifdef CONFIG_PREEMPT_RCU */
static inline void __rcu_read_lock(void)
{
preempt_disable();
}
static inline void __rcu_read_unlock(void)
{
preempt_enable();
}
static inline int rcu_preempt_depth(void)
{
return 0;
}
#endif /* #else #ifdef CONFIG_PREEMPT_RCU */
Basically the rcu_read_lock just do preempt_disable. What will happen if CPU with read critical section gets interrupt. in such cases we shall disable the interrupt on this CPU.
We can see that API table says to disable interrupts : https://lwn.net/Articles/609973/#RCU%20Per-Flavor%20API%20Table
Wait for RCU-sched read-side critical sections, preempt-disable regions, hardirqs, & NMIs
preempt_disable()/preempt_enable()
local_irq_save()/local_irq_restore()
Synchronize RCU
void synchronize_rcu(void)
{
RCU_LOCKDEP_WARN(lock_is_held(&rcu_bh_lock_map) ||
lock_is_held(&rcu_lock_map) ||
lock_is_held(&rcu_sched_lock_map),
"Illegal synchronize_rcu() in RCU read-side critical section");
if (rcu_blocking_is_gp())
return;
if (rcu_gp_is_expedited())
synchronize_rcu_expedited();
else
wait_rcu_gp(call_rcu);
}
EXPORT_SYMBOL_GPL(synchronize_rcu);
Basically synchronize is done either of these 2 functions :
1. synchronize_rcu_expedited -- looks like expedite the grace period
2. wait_rcu_gp -- looks like wait for the grace period
The comment before this function tells it all :
Wait for an RCU grace period, but expedite it. The basic idea is to IPI all non-idle non-nohz online CPUs. The IPI handler checks whether the CPU is in an RCU critical section, and if so, it sets a flag that causes the outermost rcu_read_unlock() to report the quiescent state for RCU-preempt or asks the scheduler for help for RCU-sched.
synchronize_rcu_expedited : Implementation discussion pending:
#define wait_rcu_gp(...) _wait_rcu_gp(false, __VA_ARGS__)
#define _wait_rcu_gp(checktiny, ...) \
do { \
call_rcu_func_t __crcu_array[] = { __VA_ARGS__ }; \
struct rcu_synchronize __rs_array[ARRAY_SIZE(__crcu_array)]; \
__wait_rcu_gp(checktiny, ARRAY_SIZE(__crcu_array), \
__crcu_array, __rs_array); \
} while (0)
void __wait_rcu_gp(bool checktiny, int n, call_rcu_func_t *crcu_array,
struct rcu_synchronize *rs_array)
{
int i;
int j;
/* Initialize and register callbacks for each crcu_array element. */
for (i = 0; i < n; i++) {
if (checktiny &&
(crcu_array[i] == call_rcu)) {
might_sleep();
continue;
}
init_rcu_head_on_stack(&rs_array[i].head);
init_completion(&rs_array[i].completion);
for (j = 0; j < i; j++)
if (crcu_array[j] == crcu_array[i])
break;
if (j == i)
(crcu_array[i])(&rs_array[i].head, wakeme_after_rcu);
}
/* Wait for all callbacks to be invoked. */
for (i = 0; i < n; i++) {
if (checktiny &&
(crcu_array[i] == call_rcu))
continue;
for (j = 0; j < i; j++)
if (crcu_array[j] == crcu_array[i])
break;
if (j == i)
wait_for_completion(&rs_array[i].completion);
destroy_rcu_head_on_stack(&rs_array[i].head);
}
}
EXPORT_SYMBOL_GPL(__wait_rcu_gp);
__wait_rcu_gp is initiating the completions and waiting for them to complete.
How to do synchronize_rcu() in interrupt handlers ?
The call_rcu() function may be used in a number of situations where neither synchronize_rcu() nor synchronize_rcu_expedited() would be legal, including within preempt-disable code, local_bh_disable() code, interrupt-disable code, and interrupt handlers.
call_rcu() - Queue an RCU callback for invocation after a grace period.
void call_rcu(struct rcu_head *head, rcu_callback_t func)
{
__call_rcu(head, func, -1, 0);
}
EXPORT_SYMBOL_GPL(call_rcu);
static void
__call_rcu(struct rcu_head *head, rcu_callback_t func, int cpu, bool lazy)
{
local_irq_save(flags);
...
/* Go handle any RCU core processing required. */
__call_rcu_core(rdp, head, flags);
local_irq_restore(flags);
}
Implementation TBD.
No comments:
Post a Comment